WebGIS – Allgemeine Systemarchitektur

WebGIS Ausgewählte Beispiele
Oktober 22, 2015
Trinkwasserqualität als ausgewählter Aspekt der Umweltsituation Nepals
Dezember 5, 2015
WebGIS – Allgemeine Systemarchitektur
Der zentrale Lösungsansatz beim Architekturentwurf von GIS-Software besteht darin, das System in Module mit unterschiedlichen Funktionalitäten zu unterteilen. Eine Mustervorlage stellt dabei das Drei-Schichten-Modell dar.
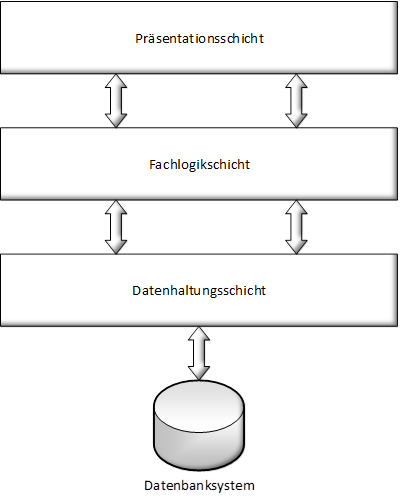
Abbildung: Drei-Schichten-Architektur eines GIS
Die Präsentationsschicht (Client Tier) besteht aus den Komponenten, die der Nutzer am Bildschirm sehen, und mit denen er das Programm bedienen kann.
Die Fachlogikschicht (Middle Tier, Application Server Tier) enthält die Module, die für die Datenverarbeitung zuständig sind.
Die Datenhaltungsschicht (Data Server Tier) dient dazu, die Geodaten auf einem Speicher zu sichern, um sie von diesem wieder abzurufen.
Aus Gründen der besseren Skalierbarkeit von Servern und der Kapselung von Internet-Technologien hat sich dieses Modell auch bei WebGIS bewährt. Die Aufteilung der Schichten erfolgt dabei auf einen Client und zwei oder mehrere Server, die alle zusammen eine verteilte Anwendung darstellen.
„Eine Verteilte Anwendung ist definiert durch eine Menge von Funktionseinheiten oder Komponenten, die in Beziehung zueinander stehen (Client-Server-Beziehung) und eine Funktion erbringen, die nicht erbracht werden kann durch die Komponenten alleine“.
Die Kernkomponenten der meisten WebGIS sind ein Client, ein Webserver, ein Kartenserver und die datei- oder datenbankbasierte Datenhaltungskomponente. Die typischen Aufgaben des Clients sind die Darstellung von Daten sowie das Stellen von Anfragen an den Kartenserver. Diese beziehen sich in der Regel auf bestimmte Karteninhalte für einen bestimmten Bereich, gegebenenfalls in tabellarischer Form, und werden zunächst vom Webserver, der als Proxy zwischen dem Client und dem Kartenserver arbeitet, empfangen, überprüft und an den Kartenserver weitergeleitet. Der Kartenserver nimmt die Anfragen entgegen, greift auf die nötigen Daten zu, erzeugt die entsprechende Bilder- oder Informationsausgabe und übergibt diese dem Webserver, der sie schließlich an den Client zurücksendet.
Nachfolgend ist ein typisches WebGIS-Modell abgebildet.
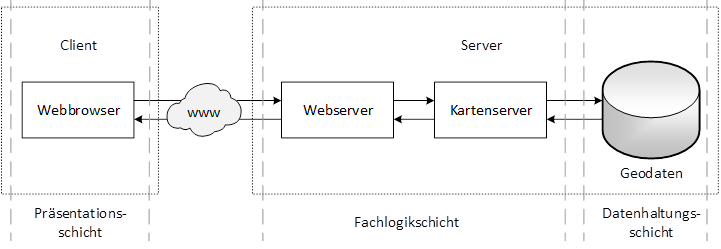
Abbildung: Typisches WebGIS-Modell
Die Geoprozessierung (Fachlogikschicht) findet grundsätzlich auf der Serverseite statt. Bei Thin-Client-Architekturen übernimmt der Client lediglich die Darstellung von Ergebnissen der serverseitigen Bearbeitung (Präsentationsschicht). Durch Erweiterungen wie JavaScript oder Plug-ins können jedoch zusätzlich clientseitige Funktionalitäten zur Verfügung gestellt werden, für die keine Kommunikation mit dem Server erforderlich ist. Damit wird die Fachlogikschicht auf den Client ausgeweitet. In diesem Fall wird von einem Fat Client gesprochen. Bei sogenannten Medium-Client-Architekturen werden Erweiterungen auf beiden Seiten realisiert. Die Datenhaltungsschicht kann aus einer Datenbank mit GIS-Funktionen bestehen, sodass sich die Fachlogikschicht auch auf die Datenhaltungsschicht ausdehnt.
Im Rahmen dieser artikel wird das in Abbildung 14 dargestellte Modell verwendet, für das folgend die Auswahl der entsprechenden Komponenten stattfindet. Ob eine Ausdehnung der Fachlogik auf die anderen Schichten erfolgt, ergibt sich aus der weiteren Konzeption.
Zuvor werden jedoch im nächsten Abschnitt die Spezifikationen des OGC behandelt, die sich aus der Anforderungsanalyse als systemrelevant ergeben haben und daher die Komponentenauswahl beeinflussen.




{kind=link}
{kind=link}